March, 22 of 2024
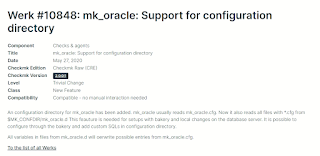
I worked on configuring the mk_oracle plugin to update the mk_oracle.cfg file to ensure that an update to the plugin wouldn't overwrite (remove) the changes for using Custom SQL, since these configurations are done manually on the host. We found a Check_MK Werk that brings us a solution to this problem: Which I documented promptly: This is a guide to deploy Custom SQLs checks for Oracle Agent. As there still isn't how to configure this in the GUI, and the Agent Bakery will overwrite the changes made directly into the mk_oracle.cfg file, this document will guide to do a safe configuration and thus avoid the overwriting of the mk_oracle.cfg file. 1) Make a directory "mk_oracle.d" inside the $MK_CONFDIR directory. Usually its /etc/check_mk #mkdir mk_oracle.d 2) Also create a directory where yours .sql files will be placed, into the same $MK_CONFDIR #mkdir sqldir 3) The sql script ouput must be as following: details: here is a breaf description over...


